Proxmox VE Backup Strategy ด้วย PBS — Retention แบบ GFS
ออกแบบ backup strategy สำหรับ Proxmox VE ด้วย PBS แบบ deduplication และ retention plan GFS พร้อมตัวอย่าง prune/GC จริง
Proxmox VE Backup Strategy ด้วย PBS — Retention แบบ GFS
ใครที่ดูแล cluster Proxmox VE หลายสิบโหนดคงคุ้นกับ vzdump เครื่องมือ backup ดั้งเดิมที่ติดมากับตัว Proxmox VE — ใช้ง่าย เซ็ตอัปไว แต่พอจำนวน VM และ container บานปลาย แล้วต้องเก็บย้อนหลังเป็นเดือนเป็นปี ข้อจำกัดเริ่มโผล่ทันที ทั้งพื้นที่ disk ที่กินไม่หยุด, backup window ที่ยืดยาว, และการ restore แบบ granular ที่แทบทำไม่ได้ บทความนี้จะอธิบายว่าทำไมถึงควรย้ายไป Proxmox Backup Server (PBS) พร้อมวิธีออกแบบ retention แบบ GFS (Grandfather–Father–Son) ที่ใช้ได้จริงบน production
ทำไมแค่ vzdump ถึงไม่พอ#
vzdump ยิง full snapshot ออกมาทุกครั้ง ไม่ว่าจะเป็น .vma.zst หรือ .tar.zst แปลว่า VM ขนาด 200 GB ที่ backup รายวันแล้วเก็บ 30 ชุด จะกินพื้นที่ขั้นต่ำ 6 TB ต่อ VM หนึ่งตัว ต่อให้บีบอัดแล้วก็ยังหนัก ที่หนักกว่านั้นคือ vzdump ไม่มี incremental backup ระดับ block ทุกรอบจึงต้องอ่าน disk ทั้งก้อนใหม่ กระทบทั้ง I/O ของ storage และ backup window อย่างหลีกเลี่ยงไม่ได้
PBS แก้โจทย์นี้ด้วย chunked storage ร่วมกับ content-defined chunking และ deduplication ระดับ datastore — block ที่ซ้ำกันข้าม snapshot หรือข้าม VM จะถูกเก็บแค่ครั้งเดียว แถม PBS ยังทำ incremental แบบ dirty-bitmap ทำให้ backup รอบที่สองเป็นต้นไปอ่านเฉพาะ block ที่เปลี่ยน ลดเวลา backup ลงได้ 5–10 เท่าในงานจริง
หลักการ deduplication + chunked store ของ PBS#
PBS จะตัดข้อมูลเป็น chunk ขนาดราว 1–4 MB ด้วย rolling hash แล้วคำนวณ SHA-256 ของแต่ละ chunk เก็บลง chunk store โดยใช้ hash เป็นชื่อไฟล์ ส่วน snapshot แต่ละชุดจะมี index file ชี้ไปยัง chunk เหล่านั้นอีกทีหนึ่ง
ผลลัพธ์ที่ตามมาคือ
- backup รอบใหม่จะส่งเฉพาะ chunk ที่ยังไม่มีใน store
- snapshot ที่เหลือเป็นแค่ metadata ก้อนเล็ก ๆ ไม่กี่ MB
- ลบ snapshot แล้ว chunk จะยังไม่หายไปทันที เพราะอาจมี snapshot อื่นอ้างอิงอยู่
จุดที่ sysadmin มือใหม่มักพลาดคือ prune ใน PBS จะลบแค่ metadata ของ snapshot เท่านั้น ส่วน chunk จริงจะค้างอยู่จนกว่าจะรัน garbage collection — แล้วก็มาบ่นกันว่า prune ไปแล้วทำไม disk ไม่ลด
ออกแบบ retention GFS — keep-daily/weekly/monthly/yearly#
GFS เป็นรูปแบบ retention ที่ใช้กันแพร่หลายในระดับ enterprise แนวคิดง่าย ๆ คือเก็บ backup ถี่ในช่วงใกล้ปัจจุบัน แล้วค่อย ๆ ห่างขึ้นเมื่อย้อนเวลาไปไกล PBS รองรับโครงสร้างนี้ตรง ๆ ผ่าน option หกตัว ได้แก่ keep-last, keep-hourly, keep-daily, keep-weekly, keep-monthly และ keep-yearly ซึ่งจะถูกประมวลผลตามลำดับ
ตัวอย่าง prune job สำหรับ workload ทั่วไป (เก็บราว 1 ปี) สร้างผ่าน proxmox-backup-manager ได้แบบนี้
proxmox-backup-manager prune-job create daily-gfs \
--store main-ds \
--schedule "daily at 22:00" \
--keep-daily 14 \
--keep-weekly 8 \
--keep-monthly 12 \
--keep-yearly 3
ชุดค่านี้แปลว่า
- เก็บ daily 14 วันล่าสุด ไว้กู้เคสใกล้ตัว เช่น user เผลอลบไฟล์
- เก็บ weekly 8 สัปดาห์ (ราว 2 เดือน) ไว้ rollback ตอน config เปลี่ยนแล้วเพิ่งมาเห็นผลทีหลัง
- เก็บ monthly 12 เดือน สำหรับ audit รายเดือนและงาน compliance
- เก็บ yearly 3 ปี สำหรับเอกสารทางบัญชี/กฎหมายที่ต้องเก็บยาว
ถ้าจะ prune แบบ manual กับ backup group ใด group หนึ่งโดยตรง ใช้ proxmox-backup-client ได้
proxmox-backup-client prune vm/101 \
--keep-daily 7 \
--keep-weekly 4 \
--keep-monthly 6 \
--dry-run true
แนะนำให้ใส่ --dry-run true ก่อนเสมอ เพื่อดูว่าระบบจะลบ snapshot ตัวไหนบ้างก่อนยิงจริง
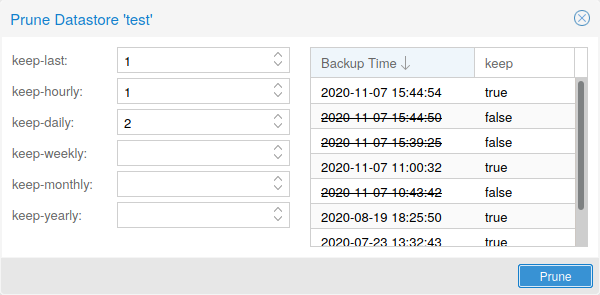
prune ไม่ได้แปลว่าลบจริง — ตอนรัน prune หรือสั่งลบ snapshot จาก UI พื้นที่ disk จะยังไม่ลดลง เพราะ PBS เพียงปลด reference ของ snapshot ออกจาก index เท่านั้น chunk ที่ไม่มีใครอ้างอิงจะถูกลบจริงก็ต่อเมื่อรัน garbage collection (GC) ซึ่งทำงานสองเฟส คือ mark phase ที่อัปเดต atime ของ chunk ที่ยังถูกใช้งาน และ sweep phase ที่ลบ chunk เก่ากว่า cutoff (ปกติ 24 ชั่วโมง 5 นาที) อย่าลืมตั้ง schedule GC ไว้รายสัปดาห์เป็นอย่างน้อย
proxmox-backup-manager datastore update main-ds \
--gc-schedule "weekly on Sunday at 23:00"
ถ้าอยากสั่ง GC ทันทีหรือเช็คสถานะ
proxmox-backup-manager garbage-collection start main-ds
proxmox-backup-manager garbage-collection status main-ds
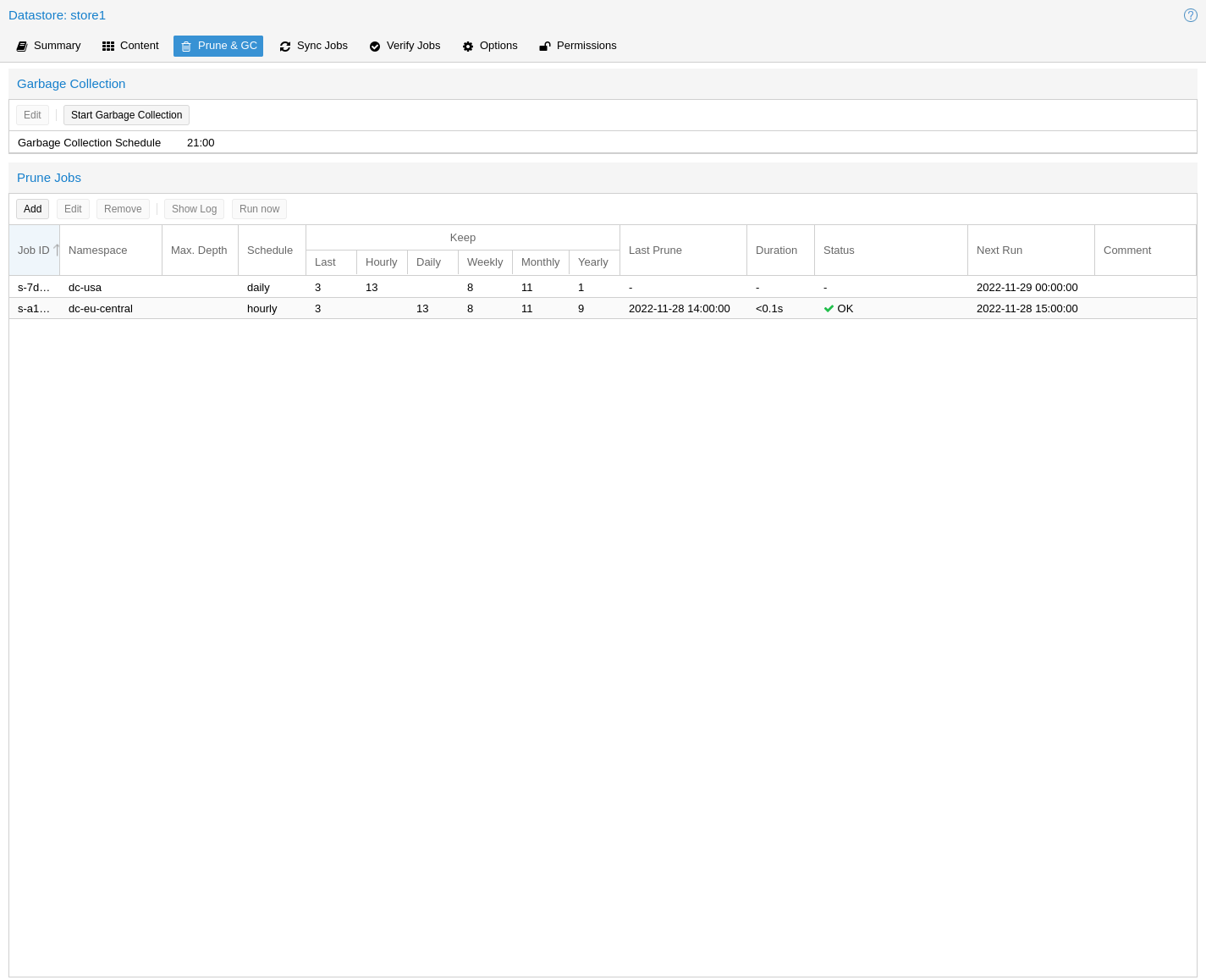
ภาพประกอบ: Proxmox Backup Server Documentation (CC BY-SA)
ลองใน Prune Simulator และซอย namespace ต่อ client — ก่อนเอา retention plan ใหม่ขึ้น production ลองใส่ค่าใน Prune Simulator ของเว็บทางการก่อน จะเห็นภาพชัดว่า snapshot ตัวไหนรอด ตัวไหนโดนลบ และถ้าให้บริการ backup กับลูกค้าหลายราย ควรซอย namespace แยกแต่ละ tenant เช่น customer-a/, customer-b/ แล้วใช้ flag --ns กับ --max-depth ใน prune job เพื่อล็อก scope — แยกได้ทั้ง quota, สิทธิ์ และ retention policy โดยไม่ปะปนกัน
สรุป + checklist#
PBS ยกระดับงาน backup ของ Proxmox VE จากเครื่องมือพื้น ๆ ให้กลายเป็นระบบ enterprise-grade ที่มีครบทั้ง deduplication, incremental, integrity verification และ retention ที่ยืดหยุ่น แต่ความสามารถทั้งหมดนี้จะออกดอกออกผลก็ต่อเมื่อทีมเข้าใจสถาปัตยกรรม chunk และมีวินัยกับ prune + GC อย่างถูกทาง
Checklist ก่อนเปิดใช้ production
- แยก datastore ตามชั้นของ storage (เช่น SSD เป็น hot tier, HDD เป็น cold)
- ซอย namespace ต่อ tenant หรือต่อ environment (
prod/,staging/) - ตั้ง prune job แบบ GFS (
keep-daily 14,keep-weekly 8,keep-monthly 12,keep-yearly 3หรือปรับตาม compliance) - ตั้ง
gc-scheduleรายสัปดาห์ทุกครั้ง ห้ามลืมเด็ดขาด - เปิด verification job อย่างน้อยเดือนละครั้ง เพื่อจับ bit rot ก่อนข้อมูลเสียเงียบ ๆ
- ทดสอบ restore จริงทุกไตรมาส — backup ที่ restore ไม่ได้ ก็เท่ากับไม่มี backup
- monitor พื้นที่ datastore ผ่าน Prometheus หรือ alert ภายในของ PBS เพื่อจับสัญญาณ chunk store บวม
ทีมที่ทำครบตาม checklist นี้จะได้ backup ที่ทั้งประหยัดพื้นที่ ทำงานไว และพร้อมกู้คืนเวลาเกิดเรื่องจริง โดยไม่ต้องมานั่งลุ้นว่า snapshot ตัวไหนใช้ได้บ้าง